Graduate Research Assistant
Department of Electrical & Systems Engineering, Washington University in St. Louis

I am a Ph.D. candidate in the Department of Electrical and Systems Engineering at Washington University in St. Louis, advised by Professor Bruno Sinopoli. My current research interests include statistical learning, uncertainty quantification, explainable AI, and control theory. I received my B.Sc. and M.Sc. degrees from Sharif University of Technology in Iran. Before joining WashU, I worked as a data scientist at Snapp. Prior to that, I was a research engineer at Fankavan Aral Group.
Electrical Engineering
Washington University in St. Louis
Thesis: High-Dimensional Data Analysis with Interpretable Low-Dimensional Models
Advisor: Professor Bruno Sinopoli
Data Analytics and Statistics
Washington University in St. Louis
Mechanical Engineering
Sharif University of Technology
Thesis: Design of Adaptive Controllers for Nonlinear Fractional-Order Systems
Advisor: Professor Hassan Salarieh
Mechanical Engineering
Sharif University of Technology
Thesis: Development of Simulation Software for Global Navigation Satellite System
Advisor: Professor Hassan Salarieh
Department of Electrical & Systems Engineering, Washington University in St. Louis
Control Laboratory, Sharif University of Technology, Tehran, Iran
My Ph.D. research focused on developing new systematic dimensionality reduction (feature extraction and selection) methods for data with complex nonlinear dependencies. This work bridges the gap between linear interpretability and nonlinear modeling power, providing new theoretical insights and practical tools for data representation. The resulting algorithms provide:
🧬 Application in Genomics: The proposed Gram-Schmidt Functional Selection (GFS) algorithm was applied to large-scale genomics datasets to remove irrelevant genes. Despite the high sparsity of such data, GFS demonstrated robust and superior performance compared to existing algorithms, which typically struggle under sparse conditions. This approach enhanced data quality, improved interpretability, and yielded more reliable and biologically meaningful insights in downstream analyses.
🖼️ Application in Deep Learning Interpretability: The GFS-CAM and NFA-CAM techniques were developed as gradient-free Class Activation Mapping (CAM) methods that apply Gram-Schmidt Functional Selection and Nonlinear Functional Analysis feature selection methods, respectively, to enhance deep neural network interpretability. These methods identify informative and non-redundant feature maps, producing clear and interpretable visual explanations that outperform state-of-the-art CAM approaches.
Beyond my core Ph.D. work, I have also explored the area of uncertainty quantification, with a particular focus on conformal prediction.
As side projects during my Ph.D., I worked on learning dynamical systems and on the safety and security of cyber-physical systems. I developed data-driven frameworks for fractional-order nonlinear systems that accurately capture long-range dependencies, and designed methods for replay attack detection and safe control in cyber-physical and drug-delivery systems, ensuring stability, robustness, and reliability in real-world applications.
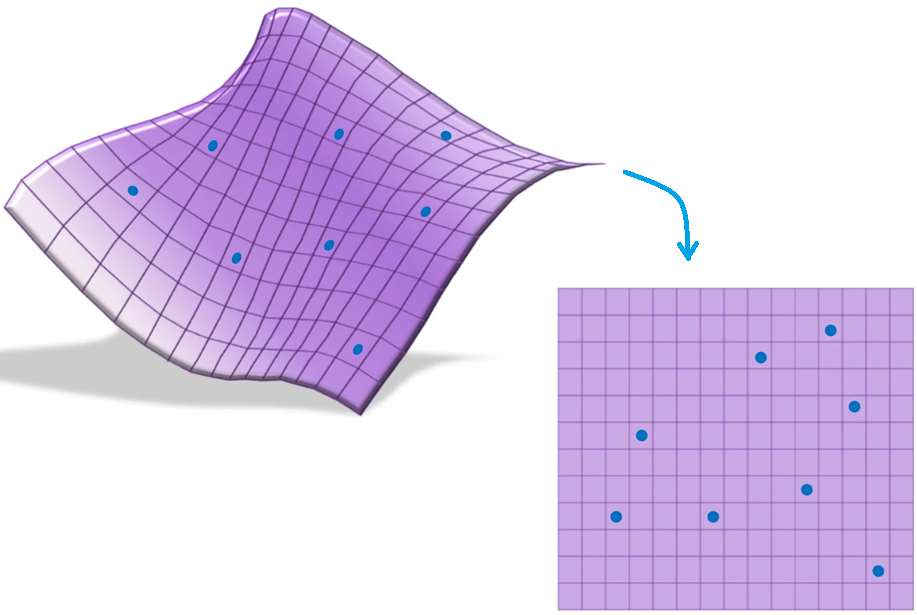
Unsupervised Feature Extraction and Selection: Feature extraction and selection in the presence of nonlinear dependencies among the data is a fundamental challenge in unsupervised learning. We propose using a Gram-Schmidt (GS) type orthogonalization process over function spaces to detect and map out such dependencies. Specifically, by applying the GS process over some family of functions, we construct a series of covariance matrices that can either be used to identify new large-variance directions, or to remove those dependencies from known directions. In the former case, we provide information-theoretic guarantees in terms of entropy reduction. In the latter, we provide precise conditions by which the chosen function family eliminates existing redundancy in the data. Each approach provides both a feature extraction and a feature selection algorithm. Our feature extraction methods are linear, and can be seen as natural generalization of principal component analysis (PCA). We provide experimental results for synthetic and real-world benchmark datasets which show superior performance over state-of-the-art (linear) feature extraction and selection algorithms. Surprisingly, our linear feature extraction algorithms are comparable and often outperform several important nonlinear feature extraction methods such as autoencoders, kernel PCA, and UMAP. Furthermore, one of our feature selection algorithms strictly generalizes a recent Fourier-based feature selection mechanism, yet at significantly reduced complexity.
Supervised Feature Selection: Supervised feature selection is essential for improving model interpretability and predictive performance, particularly in high-dimensional settings where irrelevant and redundant features can degrade classification accuracy. In this paper, we propose Supervised Gram-Schmidt Feature Selection (SGFS), a novel algorithm that iteratively selects features by leveraging the Gram-Schmidt (GS) orthogonalization process in function spaces. SGFS constructs an orthonormal basis of functions such that each selected feature maximally contributes to the classification task via the Bayes predictor. At each iteration, the algorithm updates the feature space by removing the projections of the remaining features onto the previously selected orthonormal functions, thereby identifying the feature that minimizes the Bayes error rate. By operating in function space, SGFS effectively captures nonlinear dependencies among features. We evaluate the proposed method on real-world datasets and demonstrate its superiority in classification accuracy compared to state-of-the-art feature selection techniques.

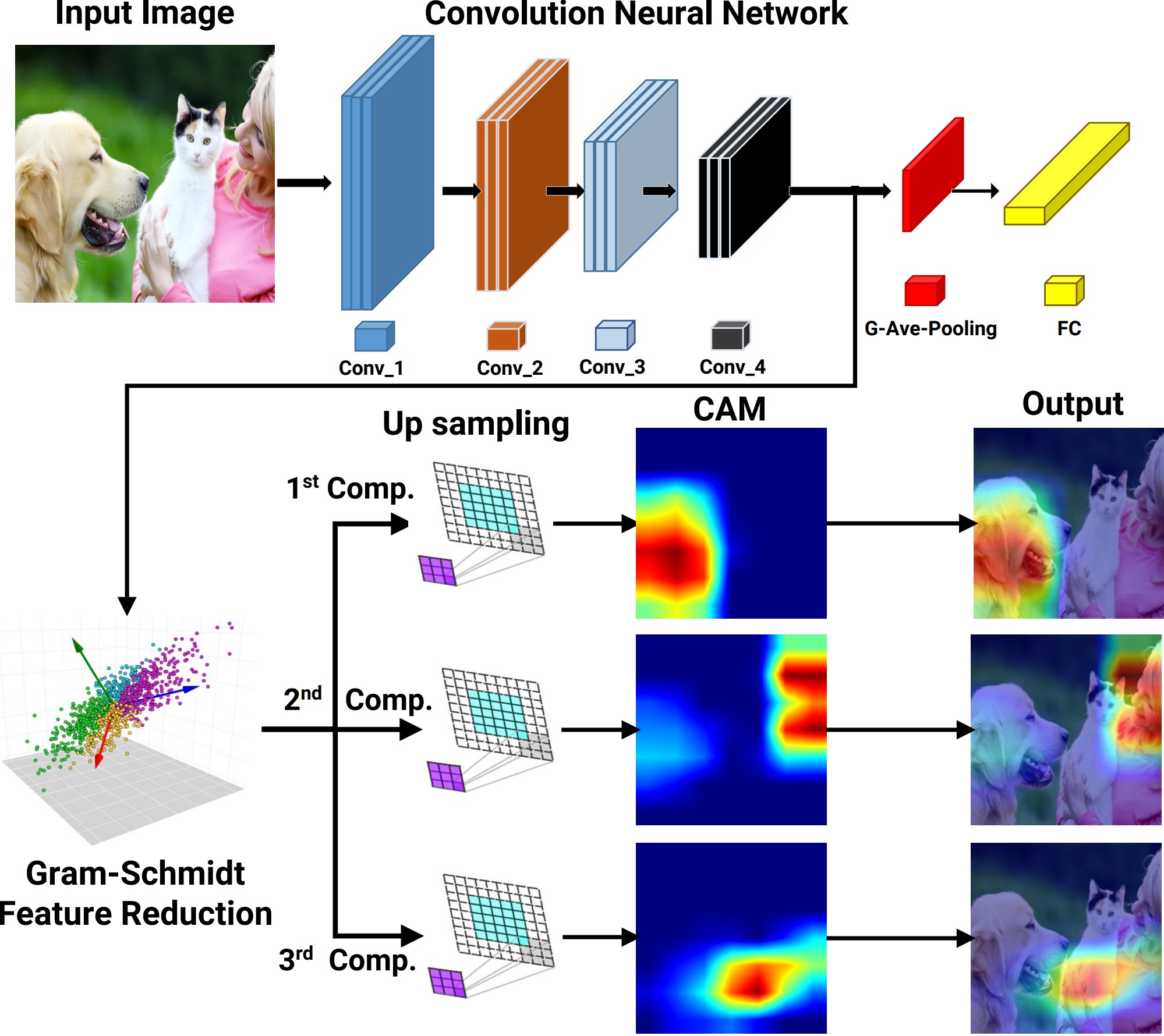
The first part of the project introduces the Gram-Schmidt Feature Reduction Class Activation Map (GFR-CAM), a novel framework designed to address the limitations of existing CAM methods in explaining deep learning models. Unlike traditional approaches that generate a single dominant explanation, GFR-CAM leverages Gram-Schmidt orthogonalization to extract a sequence of orthogonal, information-rich components from feature maps. This hierarchical decomposition provides a multi-faceted and holistic view of model reasoning, enabling richer interpretability in complex visual scenes with multiple objects or semantic parts. Experiments on ResNet-50 and Swin Transformer architectures across the ImageNet and PASCAL VOC datasets demonstrate that GFR-CAM produces meaningful, disentangled explanations while maintaining competitive performance with state-of-the-art methods.
The second part of the project develops the Gram-Schmidt Functional Selection Class Activation Map (GFS-CAM), a gradient-free interpretability method that overcomes key drawbacks of existing CAM techniques. By systematically applying Gram-Schmidt Functional Selection (GFS), the method iteratively orthogonalizes and selects feature maps that maximize residual variance, ensuring the extracted features are informative, non-redundant, and mutually orthogonal. This principled selection process allows GFS-CAM to generate disentangled explanations that separate distinct semantic concepts — such as multiple objects or background — into clear, interpretable heatmaps. Evaluations on VGG-16, Inception-v3, and ResNeXt-50 architectures with ILSVRC2012 and PASCAL VOC 2007 benchmarks confirm that GFS-CAM significantly outperforms state-of-the-art methods across faithfulness, localization, and ROAD metrics, establishing it as a powerful tool for trustworthy CNN interpretability.

Conformal Prediction for Time Series: This project introduces Conformal Prediction for Autoregressive Models (CPAM), a computationally efficient and theoretically grounded framework for reliable uncertainty quantification in time-series forecasting. Unlike standard conformal methods that assume independent data, CPAM integrates split conformal inference with classical time-series tools, combining Yule-Walker estimation, AIC-based autoregressive order selection, and residual-based calibration to construct prediction intervals with provable marginal coverage guarantees under weak temporal dependence. The method is analytically tractable, avoids repeated model refitting, and scales efficiently to large datasets. Experiments on both synthetic and real-world data, including wind power and solar irradiance forecasting, show that CPAM achieves coverage close to nominal levels while maintaining practical interval widths, making it a reliable tool for high-stakes forecasting applications.
Optimal Data Splitting for Split Conformal Prediction: This project investigates the problem of optimal data splitting in split conformal prediction, where the choice of dividing data between training and calibration has a direct impact on predictive performance. Standard approaches often use arbitrary or fixed splits, which can yield suboptimal trade-offs between model accuracy and coverage reliability. To address this limitation, the work develops a principled framework for selecting split proportions that balance the competing demands of model training and calibration, thereby improving both the efficiency and robustness of prediction intervals. Theoretical analysis and empirical results across diverse datasets demonstrate that optimal splitting produces narrower and more informative intervals while preserving rigorous coverage guarantees, providing a systematic and practical enhancement to one of the most widely used conformal prediction methods.
Conformal Prediction in Medical Imaging with Vision Transformers This project applies conformal prediction to medical imaging, with a focus on Vision Transformer (ViT) architectures to enable trustworthy AI-assisted decision-making in healthcare. While ViTs have demonstrated state-of-the-art performance in image analysis, their predictions often lack calibrated uncertainty estimates, a critical requirement for safety-sensitive clinical applications. This work integrates conformal calibration into ViT-Base and ViT-Small models, equipping them with the ability to output statistically valid and interpretable prediction sets that adapt to task complexity. The approach remains computationally efficient while delivering reliable uncertainty quantification. Evaluations on medical imaging datasets confirm that conformalized ViTs achieve robust coverage guarantees without sacrificing predictive accuracy, making them well-suited for real-world deployment in clinical decision-support systems.

Security of Cyber-Physical Systems: This project studies replay attack detection in cyber-physical systems (CPSs) through the use of physical watermarking, a well-established defense mechanism. While most watermarking approaches in the literature are designed for discrete-time systems, real-world physical systems generally evolve in continuous time. This work analyzes the effect of watermarking on sampled-data continuous-time systems controlled via a Zero-Order Hold, with a focus on how sampling impacts detection performance. A procedure is proposed to determine a suitable sampling period that balances detectability with acceptable control performance. The effectiveness of the theoretical results is demonstrated through simulations on a quadrotor system.
Safety in Drug Delivery Systems: This project develops an approach for controlling fractional-order semilinear systems subject to linear constraints, motivated by applications in drug delivery. The proposed design procedure consists of two stages: first, a linear state-feedback control law is introduced to prestabilize the system in the absence of constraints, with stability and convergence formally established using Lyapunov theory. Second, a constraint-handling mechanism based on the Explicit Reference Governor (ERG) is employed to ensure constraint satisfaction at all times. The ERG works by translating the linear constraints into bounds on the Lyapunov function and manipulating an auxiliary reference to guarantee that the Lyapunov function remains below a threshold value. The method is applied to the control of drug concentration in a drug delivery system and validated through extensive simulation results.
Feature extraction and selection in the presence of nonlinear dependencies among the data is a fundamental challenge in unsupervised learning. We propose using a Gram-Schmidt (GS) type orthogonalization process over function spaces to detect and map out such dependencies. Specifically, by applying the GS process over some family of functions, we construct a series of covariance matrices that can either be used to identify new large-variance directions, or to remove those dependencies from known directions. In the former case, we provide information-theoretic guarantees in terms of entropy reduction. In the latter, we provide precise conditions by which the chosen function family eliminates existing redundancy in the data. Each approach provides both a feature extraction and a feature selection algorithm. Our feature extraction methods are linear, and can be seen as natural generalization of principal component analysis (PCA). We provide experimental results for synthetic and real-world benchmark datasets which show superior performance over state-of-the-art (linear) feature extraction and selection algorithms. Surprisingly, our linear feature extraction algorithms are comparable and often outperform several important nonlinear feature extraction methods such as autoencoders, kernel PCA, and UMAP. Furthermore, one of our feature selection algorithms strictly generalizes a recent Fourier-based feature selection mechanism (Heidari et al., IEEE Transactions on Information Theory, 2022), yet at significantly reduced complexity.
Unsupervised feature selection is a critical task in data analysis, particularly when faced with high-dimensional datasets and complex and nonlinear dependencies among features. In this paper, we propose a family of Gram-Schmidt feature selection approaches to unsupervised feature selection that addresses the challenge of identifying non-redundant features in the presence of nonlinear dependencies. Our method leverages probabilistic Gram-Schmidt (GS) orthogonalization to detect and map out redundant features within the data. By applying the GS process to capture nonlinear dependencies through a pre-defined, fixed family of functions, we construct variance vectors that facilitate the identification of high-variance features, or the removal of these dependencies from the feature space. In the first case, we provide information-theoretic guarantees in terms of entropy reduction. In the second case, we demonstrate the efficacy of our approach by proving theoretical guarantees under certain assumptions, showcasing its ability to detect and remove nonlinear dependencies. To support our theoretical findings, we experiment over various synthetic and real-world datasets, showing superior performance in terms of classification accuracy over state-of-the-art methods. Further, our information-theoretic feature selection algorithm strictly generalizes a recently proposed Fourier-based feature selection mechanism at significantly reduced complexity.
Linear feature extraction at the presence of nonlinear dependencies among the data is a fundamental challenge in unsupervised learning. We propose using a Gram-Schmidt (GS) type orthogonalization process over function spaces in order to detect and remove redundant dimensions. Specifically, by applying the GS process over a family of functions which presumably captures the nonlinear dependencies in the data, we construct a series of covariance matrices that can either be used to identify new large-variance directions, or to remove those dependencies from the principal components. In the former case, we provide information-theoretic guarantees in terms of entropy reduction. In the latter, we prove that under certain assumptions the resulting algorithms detect and remove nonlinear dependencies whenever those dependencies lie in the linear span of the chosen function family. Both proposed methods extract linear features from the data while removing nonlinear redundancies. We provide simulation results on synthetic and real-world datasets which show improved performance over state-of-the-art feature extraction algorithms.
Supervised feature selection is essential for improving model interpretability and predictive performance, particularly in high-dimensional settings where irrelevant and redundant features can degrade classification accuracy. In this paper, we propose Bayes Error Driven Iterative Supervised Feature Selection (B-ISFS), a novel algorithm that iteratively selects features by leveraging the Gram-Schmidt orthogonalization process in function spaces. B-ISFS constructs an orthonormal basis of functions such that each selected feature maximally contributes to the classification task via the Bayes predictor. At each iteration, the algorithm updates the feature space by removing the projections of the remaining features onto the previously selected orthonormal functions, thereby identifying the feature that minimizes the Bayes misclassification error. By operating in function space, B-ISFS effectively captures nonlinear dependencies among features. We evaluate the proposed method on real-world datasets and demonstrate its superiority in classification accuracy compared to state-of-the-art feature selection techniques.
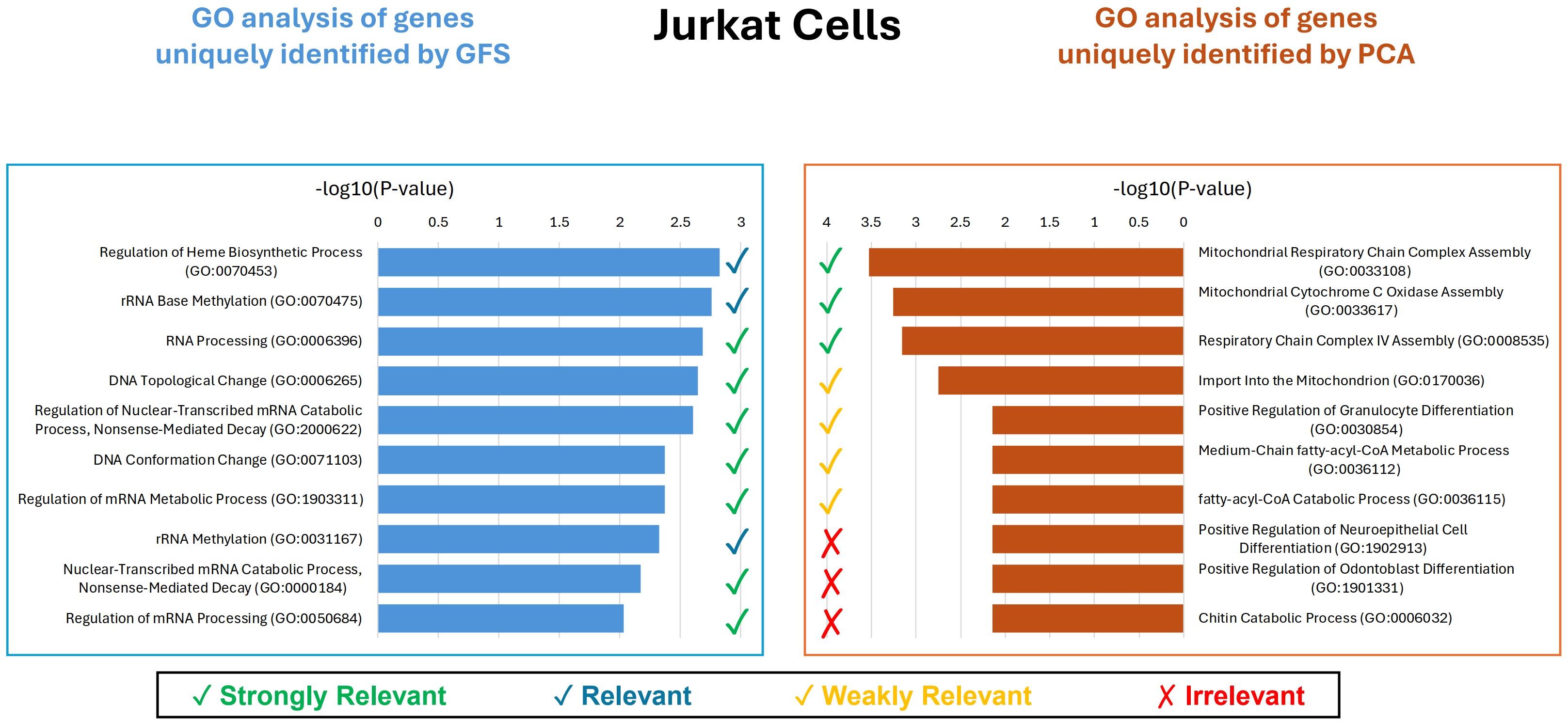
High-dimensional genomic datasets present major challenges for identifying biologically meaningful features that enhance predictive modeling while remaining interpretable. This paper proposes an interpretable framework, Gram-Schmidt Features Selection (GFS), to identify informative and minimally redundant genes through orthogonalization. The framework is evaluated on multiple benchmark gene expression datasets and compared with established feature selection methods. Results show that GFS consistently improves classification performance while reducing feature redundancy, supporting clearer model interpretation. The biological relevance of selected genes is assessed through Gene Ontology (GO) enrichment analysis, revealing significant associations with pathways and functions consistent with known cellular mechanisms. Overall, the framework demonstrates that GFS can effectively integrate predictive power with biological interpretability, offering a practical tool for selecting GO-informed genes in genomic research.
Deep Convolutional Neural Networks (CNNs) achieve remarkable performance but lack interpretability, limiting their adoption in high-stakes applications. Existing Class Activation Mapping (CAM) methods suffer from gradient noise sensitivity or computational inefficiency, while lacking principled strategies for selecting informative, non-redundant features. We introduce Gram-Schmidt Feature Selection CAM (GFS-CAM), a novel gradient-free approach that leverages Gram-Schmidt orthogonalization to construct disentangled visual explanations. Our method iteratively builds an orthogonal feature basis by selecting features that explain maximum residual variance. Unlike existing methods that generate single heatmaps, GFS-CAM isolates distinct semantic concepts into separate, interpretable maps, providing fine-grained attribution of model decisions. Extensive experiments on ILSVRC2012 and PASCAL VOC 2007 across multiple CNN architectures (VGG-16, Inception-v3, ResNeXt-50, DeiT-Base) demonstrate superior performance. GFS-CAM achieves state-of-the-art localization accuracy on three of four architectures, ranks first in 10 of 16 evaluation categories across two datasets, and attains best or second-best performance on the ROAD faithfulness benchmark across all tested CNNs. Our approach offers a principled solution that combines the robustness of gradient-free methods with computational efficiency, while providing unprecedented interpretability through feature analysis.
Visualizing deep neural network feature spaces is essential for interpretable AI, yet existing dimensionality reduction methods are fundamentally mismatched with regression tasks. Techniques like t-SNE and UMAP optimize for cluster separation, fragmenting the continuous manifolds that encode semantic meaning in regression networks and destroying geodesic distance relationships critical for model diagnosis. Manifold Discovery and Analysis (MDA) addressed this gap but relies on linear PCA preprocessing, which cannot capture manifold curvature. We propose OrthoMDA, a nonlinear extension that replaces PCA with explicit polynomial feature expansion integrated via Gram-Schmidt orthogonalization. The key insight is that degree-2 interaction terms capture second-order correlations encoding local manifold curvature, precisely the geometric information linear projections miss. Experiments across four biomedical benchmarks (brain tumor segmentation, skin lesion super-resolution, cancer survival prediction, and COVID-19 radiography) demonstrate consistent improvements of 5-32% in geodesic distance preservation over PCA-MDA, with statistical significance. OrthoMDA achieves 57% better robustness under noise perturbation and reveals generalization failures invisible to linear methods, enabling practitioners to diagnose regression DNN failures that numerical metrics alone may miss.
Writer identification in historical documents is fundamentally challenged by the non-linear entanglement of stylistic signals with degradation artifacts-physical processes such as ink bleed-through create multiplicative interactions that linear decorrelation methods cannot resolve. We present Gram-Schmidt Feature Reduction (GFR), a training-free dimensionality reduction method that achieves extended orthogonality through polynomial feature augmentation. Unlike PCA, which enforces only linear decorrelation, GFR ensures orthogonality against polynomial functions up to degree p=2, explicitly removing the interaction terms that entangle degradation with style. On the IAM-Hist and ICDAR-HWI benchmarks, GFR achieves 83.7% and 69.8% Top-1 accuracy respectively, outperforming PCA by 12.3% and 11.6%. Polynomial correlation analysis confirms a 93% reduction in quadratic dependencies, while mutual information between components decreases by 78%. Critically, GFR's later components carry 12-20% more discriminative power than PCA's, validating that polynomial orthogonalization successfully isolates stylistic information from degradation contamination. As a training-free method, GFR is immediately applicable to data-scarce historical archives where deep learning approaches are impractical.
Deep learning models have achieved remarkable success in computer vision tasks, yet their decision-making processes remain largely opaque, limiting their adoption especially in safety-critical applications. While Class Activation Maps (CAMs) have emerged as a prominent solution for visual explanation, existing methods suffer from a fundamental limitation: they produce single, consolidated explanations leading to "explanatory tunnel vision." Current CAM methods fail to capture the rich, multi-faceted reasoning that underlies model predictions, particularly in complex scenes with multiple objects or intricate visual relationships. We introduce the Gram-Schmidt Feature Reduction Class Activation Map (GFR-CAM), a novel gradient-free framework that overcomes this limitation through hierarchical feature decomposition that provides a more holistic view of the architecture's explanatory power. Unlike existing feature reduction methods that rely on Principal Component Analysis (PCA) and generate a single dominant explanation, GFR-CAM leverages Gram-Schmidt orthogonalization to systematically extract a sequence of orthogonal, information rich components from model feature maps. The subsequent orthogonal components are shown to be meaningful explanations - not mere noise, that decomposes single objects into semantic parts and systematically disentangles multi-object scenes to identify co-existing entities. We show that GFR-CAM on ResNet-50 and Swin Transformer architectures across ImageNet and PASCAL VOC datasets achieves competitive performance with state-of-the-art methods.
Reliable uncertainty quantification is essential in time-series prediction, particularly in high-stakes domains such as healthcare, finance, and energy systems, where predictive errors may lead to significant consequences. While conformal prediction (CP) provides finite-sample coverage under minimal assumptions, its extension to dependent data, such as autoregressive (AR) models, remains challenging. This paper introduces Conformal Prediction for Autoregressive Models (CPAM), a computationally efficient and theoretically grounded framework that integrates split conformal prediction with classical time-series methods. CPAM combines Yule-Walker estimation, autoregressive order selection guided by the Akaike Information Criterion, and residual-based calibration to construct prediction intervals with provable marginal coverage guarantees. The procedure is analytically tractable, avoids model refitting, and scales efficiently to large datasets. Empirical evaluations on both synthetic and real-world time series, including wind power and solar irradiance, demonstrate that CPAM consistently achieves empirical coverage close to the nominal target.
Conformal prediction provides a distribution-free framework for uncertainty quantification by constructing prediction intervals or sets with finite-sample marginal coverage guarantees. The statistical efficiency of these intervals depends critically on how the data are splitted into training and calibration samples. Despite its practical importance, a principled characterization of the training-calibration split that minimizes prediction interval length while maintaining coverage has remained largely unresolved. In this paper, we develop a theoretical framework for optimal data splitting in split conformal prediction. We first analyze the problem in a general setting and derive analytical characterizations of the length-optimal split ratio under both symmetric and asymmetric regimes. We then show how the general results specialize to several commonly used regression settings, including linear regression, nonparametric regression, and neural networks, thereby demonstrating the scope of the framework. Our analysis clarifies how model-related features govern the optimal allocation of samples between training and calibration, and provides principled guidance for constructing shorter prediction intervals. Experiments on synthetic and real-world datasets illustrate the applicability of the proposed methodology in a variety of practical scenarios.
This paper investigates the integration of conformal prediction methodologies with Vision Transformer (ViT) architectures in the context of medical imaging to enhance the reliability of AI-assisted decision-making in healthcare. Although ViTs have exhibited state-of-the-art performance in image analysis, their predictions frequently lack calibrated uncertainty estimates, a critical attribute for applications in safety-sensitive clinical environments. In this work, we incorporate conformal calibration techniques into ViT-Base and ViT-Small models, enabling them to produce statistically valid and interpretable prediction sets that dynamically adjust to task complexity. Our approach retains computational efficiency while delivering robust uncertainty quantification. Comprehensive evaluations conducted on medical imaging datasets indicate that conformalized ViTs consistently achieve stringent coverage guarantees without compromising predictive accuracy. This renders them exceptionally well-suited for deployment in clinical decision-support systems, thereby advancing the field of trustworthy and interpretable AI in healthcare.
This paper presents a data-integrated framework for learning the dynamics of fractional-order nonlinear systems in both discrete-time and continuous-time settings. The proposed framework consists of two main steps. In the first step, input-output experiments are designed to generate the necessary datasets for learning the system dynamics, including the fractional order, the drift vector field, and the control vector field. In the second step, these datasets, along with the memory-dependent property of fractional-order systems, are used to estimate the system's fractional order. The drift and control vector fields are then reconstructed using orthonormal basis functions. To validate the proposed approach, the algorithm is applied to four benchmark fractional-order systems. The results confirm the effectiveness of the proposed framework in learning the system dynamics accurately. Finally, the same datasets are used to learn equivalent integer-order models. The numerical comparisons demonstrate that fractional-order models better capture long-range dependencies, highlighting the limitations of integer-order representations.
In this paper, a system identification algorithm is proposed for control-affine, discrete-time fractional-order nonlinear systems. The proposed algorithm is a data-integrated framework that provides a mechanism for data generation and then uses this data to obtain the drift-vector, control-vector fields, and the fractional order of the system. The proposed algorithm includes two steps. In the first step, experiments are designed to generate the required data for dynamic inference. The second step utilizes the generated data in the first step to obtain the system dynamics. The memory-dependent property of fractional-order Grünwald-Letnikov difference operator is used to compute the fractional order of the system. Then, drift-vector and control-vector fields are reconstructed using orthonormal basis functions, and calculation of the coefficients is formulated as an optimization problem. Finally, simulation results are provided to illustrate the effectiveness of the proposed framework. Additionally, one of the methods for identifying integer-order systems is applied to the generated data by a fractional-order system, and the results are included to show the benefit of using a fractional-order model in long-range dependent processes.
Physical watermarking is a well established technique for replay attack detection in cyber-physical systems (CPSs). Most of the watermarking methods proposed in the literature are designed for discrete-time systems. In general real physical systems evolve in continuous time. In this paper, we analyze the effect of watermarking on sampled-data continuous-time systems controlled via a Zero-Order Hold. We investigate the effect of sampling on detection performance and we provide a procedure to find a suitable sampling period that ensures detectability and acceptable control performance. Simulations on a quadrotor system are used to illustrate the effectiveness of the theoretical results.
This paper proposes an approach to control fractional-order semilinear systems which are subject to linear constraints. The design procedure consists of two stages. First, a linear state-feedback control law is proposed to prestabilize the system in the absence of constraints. The stability and convergence properties are proved using Lyapunov theory. Then, a constraint-handling unit is utilized to enforce the constraints at all times. In particular, we use the Explicit Reference Governor (ERG) scheme. The core idea behind ERG is, first, to translate the linear constraints into a constraint on the value of the Lyapunov function, and then to manipulate the auxiliary reference such that the Lyapunov function is smaller than a threshold value at all times. The proposed method is applied in a drug delivery system to control the drug concentration, and its performance is assessed through extensive simulation results.
This article presents an adaptive nonlinear delayed feedback control scheme for stabilizing the unstable periodic orbit of unknown fractional-order chaotic systems. The proposed control framework uses the Lyapunov approach and sliding mode control technique to guarantee that the closed-loop system is asymptotically stable on a periodic trajectory sufficiently close to the unstable periodic orbit of the system. The proposed method has two significant advantages. First, it employs a direct adaptive control method, making it easy to implement this method on systems with unknown parameters. Second, the framework requires only the period of the unstable periodic orbit. The robustness of the closed-loop system against system uncertainties and external disturbances with unknown bounds is guaranteed. Simulations on fractional-order duffing and gyro systems are used to illustrate the effectiveness of the theoretical results. The simulation results demonstrate that our approach outperforms the previously developed linear feedback control method for stabilizing unstable periodic orbits in fractional-order chaotic systems, particularly in reducing steady-state error and achieving faster convergence of tracking error.
In this article, an adaptive nonlinear controller is designed to synchronize two uncertain fractional-order chaotic systems using fractional-order sliding mode control. The controller structure and adaptation laws are chosen such that asymptotic stability of the closed-loop control system is guaranteed. The adaptation laws are being calculated from a proper sliding surface using the Lyapunov stability theory. This method guarantees the closed-loop control system robustness against the system uncertainties and external disturbances. Eventually, the presented method is used to synchronize two fractional-order gyro and Duffing systems, and the numerical simulation results demonstrate the effectiveness of this method.
This article presents a robust adaptive fractional order proportional integral derivative controller for a class of uncertain fractional order nonlinear systems using fractional order sliding mode control. The goal is to achieve closed-loop control system robustness against the system uncertainty and external disturbance. The fractional order proportional integral derivative controller gains are adjustable and will be updated using the gradient method from a proper sliding surface. A supervisory controller is used to guarantee the stability of the closed-loop fractional order proportional integral derivative control system. Finally, fractional order Duffing–Holmes system is used to verify the proposed method.



C/C++, Python (NumPy, Pandas, Matplotlib, Seaborn, Scikit-learn, TensorFlow, PyTorch, Keras, Transformers, torchvision), MATLAB & Simulink
ARM (IAR Embedded Workbench), AVR (CodeVisionAVR), Arduino
SolidWorks, Abaqus, ANSYS (Workbench), Nastran & Patran
ADAMS
LabVIEW, Automation Studio
Proteus
Teaching Assistant, Linear Dynamic Systems I
Instructor: Prof. Bruno Sinopoli
Teaching Assistant, Mathematics of Modern Engineering II
Instructor: Prof. Vladimir Kurenok
Teaching Assistant, Automatic Control
Instructor: Prof. Hassan Salarieh
Teaching Assistant, Linear Dynamic Systems
Instructor: Prof. Aria Alasty
Teaching Assistant, Nonlinear Control
Instructor: Prof. Gholamreza Vossoughi
Teaching Assistant, Mechatronics Lab.
Instructor: Prof. Gholamreza Vossoughi
Ph.D. Fellowship Award from Washington University in St. Louis.
Ph.D. Fellowship Award from University of Minnesota.
Ranked 4th among more than 20,000 Participants in Nationwide Entrance Exam for M.Sc. Degree in Mechanical Engineering.
Ranked 9th in the National Mechanical Engineering Olympiad.
Ranked 116th among more than 310,000 Participants in the Iranian Nationwide Entrance Exam for B.Sc. Degree.
I would be happy to collaborate on research projects and contribute my expertise.
Washington University in St. Louis, St. Louis, MO
Department of Electrical and Systems Engineering